Laboratorio 7 : Metodi Stazionari per Sistemi Lineari
Contents
Laboratorio 7 : Metodi Stazionari per Sistemi Lineari#
Un metodo iterativo è una procedura matematica che a partire da un valore iniziale genera una sequenza di soluzioni approssimate migliorative per una determinata classe di problemi, in cui l’approssimazione \(n\)esima è derivata dai precedenti. Abbiamo già visto, ed implementato, metodi di questo tipo per la ricerca degli zeri di una funzione.
In questo laboratorio vogliamo concentrarci invece sulla costruzione di alcuni metodi di questo tipo per la soluzione di sistemi lineari.
La prima domanda che è legittimo porsi è perché mai vogliamo mettere in piedi dei metodi iterativi se abbiamo già dei metodi diretti che possono raggiungere la soluzione del problema cercato?
A patto di richiedere una tolleranza minore (spesso sufficiente nelle applicazioni) sull’errore commesso sulla soluzione hanno un costo computazionale inferiore alle controparti dirette,
Per le dimensioni dei problemi che si vogliono affrontare nelle applicazioni ingegneristiche attuali sono spesso l’unica opzione disponibile (problemi di fluidodinamica computazionale, combustione, meccanica del continuo, …)
Nel corso e in questo laboratorio ci focalizziamo su alcuni dei metodi più semplici e che, in genere, sono usati come i blocchi costituivi di metodi più complessi (e.g., metodi di tipo multigrid o domain decomposition) o come acceleratori per la convergenza (in gergo chiamati: precondizionatori).
Metodi di tipo stazionario#
Dato un sistema lineare della forma
siamo interessati a metodi di punto fisso basati sugli splitting della matrice \(A\). Cioè metodi basati su una decomposizione additiva della matrice della forma
Da questa decomposizione si ottiene poi l’iterata di punto fisso come
e quindi
Essendo questa un’iterata di punto fisso, la sua convergenza dipende dall’essere una procedura contrattiva, avete dimostrato a lezione che questo è equivalente alla richiesta che il raggio spettrale della matrice di iterazione \(M^{-1}N\) sia strettamente minore di \(1\):
Metodi per il calcolo agli autovalori implementati in MATLAB#
In alcuni casi data una matrice \(A\) e uno splitting \(A = M - N\) è possibile calcolare il raggio spettrale carta e penna, oppure inferire le proprietà di convergenza del metodo dalle proprietà della matrice \(A\) e della particolare forma dello splitting. Laddove questo non fosse possibile, o volessimo una stima più precisa di quello che sta accadendo, dobbiamo ricorrere a dei metodi numerici a questo scopo. La loro costruzione è al di fuori degli obiettivi di questo corso, tuttavia MATLAB ci fornisce delle function che fanno al nostro caso.
Vediamo prima il caso generale in cui data una matrice \(A\) vogliamo calcolare tutti i suoi autovalori, costruiamo da principio una matrice simmetrica per cui possiamo sfruttare il Teorema Spettrale per interpretare i risultati:
A = rand(10); % costruiamo una matrice casuale
A = A + A'; % e facciamo in modo che sia simmetrica
lambda = eig(A); % calcoliamo *tutti* gli autovalori
disp(lambda)
che ci restituisce il vettore:
-2.1767
-1.8198
-0.7091
-0.3270
-0.1747
0.7953
0.9842
1.3664
1.9277
9.4423
per cui abbiamo ottenuto 10 autovalori reali.
Se guardiamo il manuale del comando eig leggiamo:
eig Eigenvalues and eigenvectors.
E = eig(A) produces a column vector E containing the eigenvalues of
a square matrix A.
[V,D] = eig(A) produces a diagonal matrix D of eigenvalues and
a full matrix V whose columns are the corresponding eigenvectors
so that A*V = V*D.
[V,D,W] = eig(A) also produces a full matrix W whose columns are the
corresponding left eigenvectors so that W'*A = D*W'.
Possiamo quindi usarlo per ottenere anche le relativi matrici degli autovettori sinistri e destri per la matrice \(A\), cioè le matrici \(V\) e \(W\) tali che:
Pericolo
MATLAB, e la maggior parte degli algoritmi che calcolano autovalori, non conoscono la forma canonica di Jordan e l’esistenza di matrici non diagonalizzabili. Per cui vi restituiranno sempre una diagonalizzazione, anche quando questa non esiste. Consideriamo ad esempio il blocco di Jordan:
J = gallery('jordbloc',5)
[V,D,W] = eig(J)
Otteniamo le due matrici, senza warning o altro… tuttavia se calcoliamo
cond(V)
ans =
1.3009e+63
che è un valore enorme per una matrice \(5 \times 5\). Questo ci deve far sospettare che c’è qualcosa che non va!
Per calcolare direttamente il raggio spettrale della matrice \(M^{-1}N\) non abbiamo in realtà la necessità di calcolare tutti gli autovalori della matrice e prendere il massimo. Possiamo accedere ad algoritmi che calcolano direttamente la quantità che ci interessa:
A = gallery('poisson',5); % Discretizzazione del Laplaciano in 2D
M = diag(A); % A = M - N
N = M-A; % N = M - A
rho = eigs(N,M,1,'largestabs');
disp(abs(rho))
che ci restituisce il valore 0.8660 per il raggio spettrale, cioè abbiamo trovato uno splitting convergente.
Vediamo il manuale del comando eigs.
eigs Find a few eigenvalues and eigenvectors of a matrix
D = eigs(A) returns a vector of A's 6 largest magnitude eigenvalues.
A must be square and should be large and sparse.
[...]
eigs(A,K,SIGMA) and eigs(A,B,K,SIGMA) return K eigenvalues. If SIGMA is:
'largestabs' or 'smallestabs' - largest or smallest magnitude
'largestreal' or 'smallestreal' - largest or smallest real part
'bothendsreal' - K/2 values with largest and
smallest real part, respectively
(one more from largest if K is odd)
For nonsymmetric problems, SIGMA can also be:
'largestimag' or 'smallestimag' - largest or smallest imaginary part
'bothendsimag' - K/2 values with largest and
smallest imaginary part, respectively
(one more from largest if K is odd)
If SIGMA is a real or complex scalar including 0, eigs finds the
eigenvalues closest to SIGMA.
da cui leggiamo che quello che abbiamo chiesto a MATLAB di calcolare è un autovalore (1) di massimo valore assoluto ('largestabs') che risolva il problema
che, nel nostro caso, è equivalente alla richiesta
cioè quello che cercavamo. Problemi di questa forma sono detti problemi generalizzati agli autovalori, ma sono ben al di fuori degli obiettivi di questo corso.
Avvertimento
Tutte le volte che volete risolvere un problema agli autovalori con matrice \(M^{1}N\) la soluzione opportuna è quella di usare la formulazione come problema generalizzato agli autovalori, sia da un punto di vista di stabilità numerica, sia da un punto di vista di velocità di esecuzione del codice.
Metodo di Jacobi#
Il primo metodo che vogliamo implementare è il metodo di Jacobi, questo è basato sullo splitting additivo per la matrice \(A\) con \(A = D - N\) dove \(D\) è la diagonale della matrice \(A\).
Teorema
Una condizione sufficiente (ma non necessaria) affinché il metodo di Jacobi sia convergente è che la matrice \(A\) sia a diagonale strettamente dominante, oppure a diagonale dominante e irriducibile.
Per trasformare il metodo in qualcosa di applicabile dobbiamo accoppiarlo ad un criterio d’arresto. Come sempre possiamo guardare al residuo assoluto oppure a quello relativo in una norma prefissata. Poiché abbiamo deciso di guardare alla convergenza attraverso informazioni spettrali scelta più naturale (e predittiva) è quella di usare la norma \(\|\cdot\|_ 2\).
ovvero, rispettivamente
dove \(\varepsilon\) è una tolleranza prefissata.
Esercizio
Si scriva una function che implementi il metodo di Jacobi per la soluzione di un sistema lineare \(A \mathbf{x} = \mathbf{y}\) entro una tolleranza \(\varepsilon\) sfruttando il seguente prototipo:
function [x,res,it] = jacobi(A,b,x,itmax,eps)
%%JACOBI implementa il metodo di Jacobi per la soluzione del sistema A x = b
% INPUT:
% A matrice quadrata
% b termine destro del sistema lineare da risolvere
% x innesco della strategia iterativa
% itmax massimo numero di iterazioni lineari consentito
% OUTPUT
% x ultima soluzione calcolata dal metodo
% res vettore dei residui
% it numero di iterazioni
end
Si implementi in maniera vettoriale, cioè senza usare cicli
forper scorrere le righe della matrice,Si usi il criterio d’arresto basato sull’errore relativo.
Per testare il metodo si usi il seguente programma
A = gallery('poisson',10); % Matrice di prova
b = ones(10^2,1); % rhs vettore di 1
x = zeros(10^2,1); % Tentativo iniziale vettore di 0
[x,res,it] = jacobi(A,b,x,1000,1e-6);
figure(1)
semilogy(1:it,res,'o-','LineWidth',2);
xlabel('Iterazione');
ylabel('Residuo relativo');
Metodo di Gauss-Seidel#
Il secondo metodo di questo tipo che avete visto è il metodo di Gauss-Seidel, per questo metodo la decomposizione additiva della matrice \(A\) è \(A = L - N\), dove \(L\) è la parte triangolare inferiore della matrice \(A\).
Teorema
Una condizione sufficiente (ma non necessaria) affinché il metodo di Gauss-Seidel sia convergente è che la matrice \(A\) sia a diagonale strettamente dominante, oppure una matrice simmetrica e definita positiva.
Possiamo sfruttare di nuovo il residuo relativo per definire il criterio d’arresto.
Esercizio
Si scriva una function che implementi il metodo di Gauss-Seidel in avanti per la soluzione di un sistema lineare \(A \mathbf{x} = \mathbf{y}\) entro una tolleranza \(\varepsilon\) sfruttando il seguente prototipo:
function [x,res,it] = forwardgs(A,b,x,itmax,eps)
%%FORWARDGS implementa il metodo di Gauss-Seidel in avanti per la soluzione del
% sistema A x = b
% INPUT:
% A matrice quadrata
% b termine destro del sistema lineare da risolvere
% x innesco della strategia iterativa
% itmax massimo numero di iterazioni lineari consentito
% OUTPUT
% x ultima soluzione calcolata dal metodo
% res vettore dei residui
% it numero di iterazioni
end
Si implementi in maniera vettoriale, cioè senza usare cicli
forper scorrere le righe della matrice,Si utilizzi la funzione
forwardsolvevista in Sostituzione in avanti e all’indietroSi usi il criterio d’arresto basato sull’errore relativo.
Per testare il metodo si usi il seguente programma
A = gallery('poisson',10); % Matrice di prova
b = ones(10^2,1); % rhs vettore di 1
x = zeros(10^2,1); % Tentativo iniziale vettore di 0
[x,res,it] = forwardgs(A,b,x,1000,1e-6);
figure(1)
semilogy(1:it,res,'o-','LineWidth',2);
xlabel('Iterazione');
ylabel('Residuo relativo');
Paragone tra i due metodi e velocità di convergenza#
Adesso che abbiamo implementato i due diversi metodi possiamo fare un confronto delle loro prestazioni. Possiamo paragonare in primo luogo le due storie di convergenza guardando all’evoluzione dei residui:
A = gallery('poisson',10); % Matrice di prova
b = ones(10^2,1); % rhs vettore di 1
x = zeros(10^2,1); % Tentativo iniziale vettore di 0
[xjacobi,resjacobi,itjacobi] = jacobi(A,b,x,1000,1e-6);
[xforwardgs,resforwardgs,itforwardgs] = forwardgs(A,b,x,1000,1e-6);
figure(1)
semilogy(1:itjacobi,resjacobi,'o-',...
1:itforwardgs,resforwardgs,'x-', 'LineWidth',2);
xlabel('Iterazione');
ylabel('Residuo');
legend({'Jacobi','Gauss-Seidel (Forward)'},...
'Location','northeast',...
'FontSize',14);
Da cui osserviamo che il metodo di Gauss-Seidel (forward) impiega meno iterazioni per raggiungere la convergenza desiderata (Fig. 17).
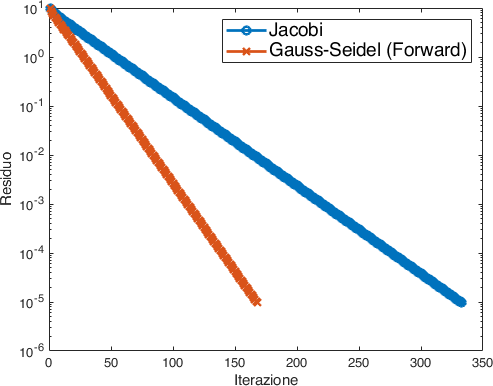
Fig. 17 Evoluzione del residuo per i metodi di Jacobi e Gauss-Seidel.#
Possiamo indagare la cosa dal punto di vista teorico andando a guardare il raggio spettrale delle due matrici di iterazione, infatti
M = diag(diag(A)); % Jacobi
N = M - A;
rhojacobi = eigs(N,M,1,'largestabs');
M = tril(A); % Gauss-Seidel (forward)
N = M - A;
rhoforwardgs = eigs(N,M,1,'largestabs');
fprintf('Il raggio spettrale per Jacobi è %f\n',abs(rhojacobi));
fprintf('Il raggio spettrale per Gauss-Seidel è %f\n',abs(rhoforwardgs));
Da cui scopriamo che:
Il raggio spettrale per Jacobi è 0.959493
Il raggio spettrale per Gauss-Seidel è 0.920627
dunque Gauss-Seidel (forward) ha un tasso di riduzione del residuo minore e una convergenza più rapida.
Possiamo aggiungere delle istruzioni tic e toc per valutare anche il tempo impiegato dai due differenti metodi:
Il tempo per Jacobi è 0.008983 s
Il tempo per Gauss-Seidel è 0.182575 s
ovvero il metodo di Jacobi è in questo caso circa due ordini di grandezza più rapido. Tuttavia, se andiamo a sostituire la nostra implementazione della funzione forwardsolve con il \ implementato da MATLAB scopriamo che:
Il tempo per Jacobi è 0.008191 s
Il tempo per Gauss-Seidel è 0.004435 s
ed ora Gauss-Seidel ha ampiamente recuperato su Jacobi. L”implementazione conta! Qui il vantaggio è dato dal fatto che la matrice \(L\) associata al problema di test che stiamo guardando è una matrice a banda i non-zeri non riempiono tutto il triangolo. Il codice di MATLAB è in grado di accorgersene e adatto l’algoritmo di soluzione in modo che se ne tenga conto.